Hace casi un mes se realizó (en Portland, OR, EEUU) la
JSConf 2011, y estuve leyendo sobre algunas de las presentaciones, algunas muy interesantes, ya no es novedad que éste es un momento muy especial para el mundo Javascript.
NodeConf
Un poco al margen de esta nota es destacable que a continuación de la JSConf se realizó la
NodeConf, cada una de 2 días de duración, una pauta de la importancia que está cobrando
Node.js, lo cual también puede verse en el impresionante crecimiento en la cantidad de
modulos desarrollados por terceros, más de 20 se agregaron en los últimos 9 días).
Dos estilos
Volviendo al JSConf, quiero compilar en este artículo uno de los temas que vi emerger en varios blogs de los asistentes, y es la aparición a lo largo de la conferencia de 2 estilos distinguibles de aplicaciones web, en lo que al cliente se refiere (no voy a hablar de Asp.Net, PHP, Node.js o Ruby on Rails, sino de HTML+CSS+JS).
Si bien no tienen nombres definidos voy a nombrar estos estilos por sus rasgos más representativos, voy a hablar de aplicaciones "Progressive Enhancement" (en adelante PE) y aplicaciones "MVC", "MVVM" o "MVVMC" (en adelante MVC), describiendo sus características quedará más claro a que me refiero.
Aplicaciones "Progressive Enhancement"
El termino "Progressive Enhancement" hace referencia a una práctica muy difundida en JavaScript en la que las páginas se descargan al cliente con funcionalidad básica, una vez completada la descarga mediante Javascript, se incrementa de forma
progresiva la usabilidad, y en algún caso la funcionalidad a medida que se detecta soporte en el navegador para las tecnologías requeridas.
Un ejemplo simple: imaginemos una página en la que se le solicita al usuario ingresar su ubicación geográfica para ofrecerle algún servicio. Siguiendo el principio de "Progressive Enhancement" podría estar construída de esta manera:
- La página llega al cliente con un simple textbox en el cual el usuario ingresa su dirección (calle y número), al hacer click en enviar el formulario se envía al server, en el server se traduce esa dirección en coordenadas geográficas invocando por ej. a la API de Google Maps. Luego se devuelve al cliente una página con la dirección normalizada a modo de confirmación.
- En caso de detectar un cliente de escritorio o con suficiente resolución de pantalla se agrega a la página de confirmación un mapa (como imagen estática) con la ubicación encontrada señalada, ésta imagen puede generarse con la Static API de GMaps.
- Si se detecta en el navegador soporte para Javascript, al completarse la descarga del formulario se agrega debajo del textbox un mapa interactivo de GMaps dónde el usuario puede seleccionar su ubicación haciendo click en el mapa.
- Si luego de detectarse soporte para Javascript se detecta también soporte para geo-localización (HTML5) se utiliza este servicio para obtener la ubicación actual y mostrarla como valor default en el mapa.
El resultado es que el cliente obtiene la mejor experiencia posible en base a las capacidades del navegador/dispositivo que utiliza.
Típicamente se trata de páginas que en su mínima expresión se comportan como páginas con HTML (y CSS) que permite navegar, manipular o enviar contenido con los elementos disponibles del HTML estático (anchors y forms). Y van incrementando su usabilidad, responsividad e inclusive su funcionalidad, a medida que se detecta soporte para Javascript, manipulación del DOM, procesamiento de información del lado cliente, comunicación asincrónica con el server (AJAX) y otras técnicas soportadas por las APIs de HTML5 (como geolocalización, modo "offline" o base de datos local).
PE tiene el mismo objetivo que "Graceful Degradation" pero utiliza el camino reverso, con "Graceful Degradation" la página llega al cliente en su "máxima expresión" y se maneja de la manera más "agraciada" posible la falta de soporte del cliente presentando alternativas de menores requerimientos. A la larga la experiencia del usuario puede ser similar con ambos approaches, pero PE es a veces visto como una evolución de GD por hacer a un mejor diseño y uso eficiente de los recursos, pero ambos pueden ser convenientes según el escenario.
Finalmente cabe mencionar que PE o GD no sólo aplican a Javascript o APIs HTML5, también aplica a diferentes resoluciones de pantalla (como muestra el punto 2 del ejemplo), o al uso de estilos más sofisticados de CSS3 (gradientes, esquinas redondeadas, etc.). Dejo este tipo de PE/GD para otro momento ya que son transversales al tema de este artículo ya que aplican a tanto a las que llamé aplicaciones PE como MVC. Quedaría para otro artículo en que hablemos por ejemplo de el uso condicional de estilos usando
modernizr.
La construcción de aplicaciones PE suele estar soportada por el uso extensivo de frameworks como jQuery, Prototype o MooTools (o una combinación de microframeworks). A la hora de implementar los diferentes items de "mejora" progresiva es importante respetar la buena práctica de "
Feature detection over Browser Sniffing", es decir utilizar siempre la detección de soporte para una deteminada API en lugar de intentar detectar el nombre o versión del navegador (ya sea en base a
window.navigator o a la existencia de cierta función). Existen algunas librerías para facilitar el uso de "Feature detection",
modernizr es la más famosa (
ahora se incluye por default en los proyectos Asp.Net Mvc 3).
En conclusión, todo esto no es en realidad ninguna sorpresa, todas las aplicaciones web que usamos a diario han migrado o están migrando a este estilo, el cual seguramente siga siendo predominante por mucho tiempo.
Aplicaciones MVC o MVVM
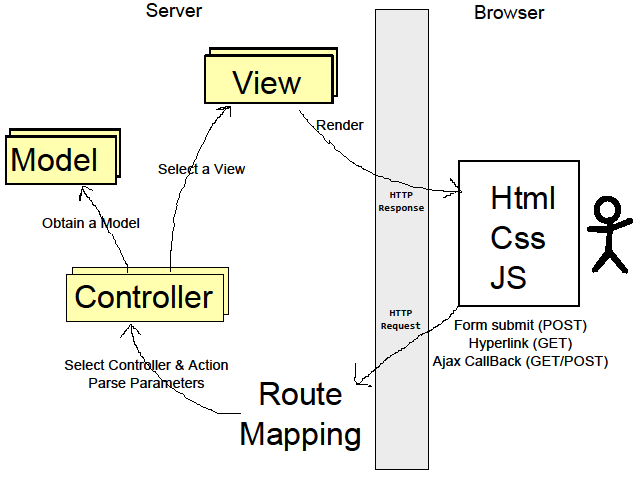
Por otro lado, existe otro estilo marcadamente diferente del anterior. Se trata de aplicaciones que implementan el patrón MVC (Model-View-Controller) o alguna variante MVVM (Model-View-ViewModel), MVVMC (Model-View-ViewModel-Controler) completamente del lado del cliente, el resultado es una arquitectura similar a la que permiten otras plataformas RIA, como Silverlight (véase Silverlight MVVM) o JavaFX pero con las ventajas de basarse únicamente en HTML+CSS+JS.
En estas aplicaciones toda la lógica de presentación se encuentra en el cliente, lo que permite utilizar como BackEnd nada más que una capa de servicios REST+JSON que se encargue de lógica de negocios, persistencia, y conectividad con otros servicios (agrego un diagrama de arquitectura más adelante).
Generalmente se trata de aplicaciones que se descargan como una única página html (single-page apps), que contiene el layout principal. Luego se realiza la carga e de algun framework JavaScript MVC (Backbone, Sproutcore, JavascriptMVC) o MVVM (Knockout.js, Batman.js).
Generalmente se encargan de coordinar el envío y recepción de datos via AJAX, y actualizar la UI (vistas) mediante el uso algún motor de templates para Javascript (
jQuery.templates,
EJS,
mustache) o mediante la manipulación de bloques html decorados con metadata (clases css o atributos data-*), vistas "template-less".
Este última modalidad (template-less) es el caso de
Batman.js, un framework MVVM cuya uso de "Convention over Configuration" le da una simplicidad increíble, les recomiendo ver
alguno de los ejemplos que hay en la página oficial. Sólo les falta mejorar un poco el logo!
En general, estos frameworks permiten definir modelos de entidades, aplicar databinding bidireccional, y configurar algún manejo de persistencia (por ejemplo Batman.js permite seleccionar entre almacenamiento local (HTML5), websockets (lo que permite colaboración en tiempo real) o el uso de un adaptador para otras bases de datos).
Cada vez vemos más aplicación HTML con UI complejas (en su estructura y en su interactividad) el resultado suele ser un caótico rejunte de scripts (ya sea en files separados o embebidos) formada principalmente por una serie de métodos que manejan el input del usuario a traves eventos DOM: muchas líneas como éstas:
$('#refresh').click(function(e) {
...
});
$('.item-row').hover(function(e) {
...
});
$('#btn-send').click(function(e) {
$.ajax({...
success: function(data){
$('#item-list').empty()
.append(...)
.children('.item')
.css({color:'red'}).end()
.fadeIn(function(){
$('#progressbar').hide();
});
}
});
});
(Nótese la clásica "pirámide" con callback asincrónico incluído)
Afortunadamente este problema es muy antigüo y como suele suceder existe un patrón que lo resuelve muy bien. El problema es simplicar la construcción de interfaces de usuario inherentemente complejas y el patrón más conocido para atacarlo es MVC y lo hace mediante la aplicación de SoC (separación de responsabilidades). Con lo cual no debería sorprender el surgimiento de éstas librerías.
A diferencia de las anteriores éstas aplicaciones están pensadas para proveer una experiencia de usuario al nivel de las aplicaciones de escritorio, pero con todas las bondades de la web, portabilidad, actualizaciones, sandboxing, etc. (hasta acá el lema de cualquier plataforma RIA) pero con la simplicidad de desarrollar sobre los estándares HTML+CSS+JS, stack que hoy en día todo desarrollador y diseñador web se ve obligado a dominar.
Escenarios
Quizás sea demasiado pronto para identificar escenarios recomendados para uno y otro (al menos para mí) pero si se puede ir pensando en los trade-offs entre un estilo y el otro. Pero antes de empezar a hacer comparaciones es importante la siguiente consideración: no se trata de modelos excluyentes, ambos pueden convivir en una aplicación (inclusive en una misma página!), en vez de en 2 modelos alternativos podríamos pensar en un gradiente como este:
En un extremo del gradiente se ubican páginas de HTML estático, cuya única forma de interacción son links y formularios "planos", sin javascript. Salvo que se trate de un web site simple (en opuesto a una web application), tendremos en el server gran parte de la lógica de presentación y de navegación, y también prácticamente toda la lógica de negocios, la "responsividad" no es su fuerte y depende de la conexión.
En el otro extremo podemos ubicar las aplicaciones puramente MVC, en las que toda la lógica de presentación se maneja del lado cliente, así como una parte de la lógica de negocios, la responsividad es óptima y no depende de la conexión, inclusive pueden trabajar "offline" de forma esporádica o permanente.
Dónde están las aplicaciones "Progressive Enhancement"? Cómo se ve en el gráfico se "mueven" adaptativamente (según las capacidades de cada navegador) en un rango del gradiente, la granularidad y la amplitud del rango dependerá de como sean construídas en base a requerimientos.
Sobre el gradiente señale algunas de las variables (que encontré más significativas) que se crecen o decrecen con este gradiente, anticipándome a lo siguiente:
Trade-offs
Portabilidad
Esta es a primera vista una ventaja evidente del primer estilo, ya que a esto apunta PE. Las aplicaciones construídas de esta manera se adaptan dinámicamente a las capacidades del navegador o dispositivo cliente.
Sin embargo es probable que éste punto se vuelva cada vez menos decisivo con el tiempo.
Las aplicaciones MVC tienden a requerir motores Javascript más poderosos y dependiendo del caso algunos features de HTML5, sin embargo ambas cosas son cada vez más fáciles de encontrar en cualquier dispositivo moderno.
En computadores personales, el único escollo son las versiones de Internet Explorer, 6, 7 y 8, que desaparecen más lento de lo que quisiéramos:
http://deathtoie6.com/. Sin embargo es posible actualizarse en todas las plataformas. En WinXP sólo puede llegarse hasta IE8, pero puede instalarse Chrome y otros navegadores en sus últimas versiones.
Todos las nuevas versiones de navegadores salen a competir con rimbombantes benchmarks de sus motores Javascript (IE9 es el último en incorporarse a esta especie de "guerra fría" y lo hizo con una comparación de IE9 vs Chrome (al estilo desafío Pecsi) en una de las Keynotes del MIX2011. Y en el keynote de Google I/O 2011 también hubo una demostración en este sentido).
En los dispositivos móviles de última generación (IPad, IPhone, Android, RIM, etc.) motores Javascript modernos y soporte para HTML5 es más fácil de encontrar que cualquier plugin de tecnologías RIA (Flash, Silverlight). Inclusive ya hay herramientas para construir aplicaciones usando HTML+CSS+JS que logran el mismo "look and feel" y acceden a las mismas APIs que las aplicaciones nativas en todas estas plataformas moviles (
PhoneGap, AppCelerator Titanium) y con Android es probable que dento de poco podamos dispongamos de HTML5+CSS3+JS en TVs, heladeras y lavarropas :)
Por todo esto, las ventajas en portabilidad a la hora de implementar PE empiezan a desdibujarse.
SEO
Este es punto está claramente a favor de PE y probablemente siempre lo esté. Las aplicaciones MVC simplemente no son indexables al igual que las demás tecnologías RIA, salvo que se recurra a los mismos "trucos" que se utilizan hoy en día en otras RIA, que implican en mayor o menor medida duplicar, o generar un duplicado del contenido que sea indexable.
Si SEO es importante para nosotros necesitamos que nuestro sitio pueda moverse dignamente hasta el extremo izquierdo del gradiente, sin embargo hay que tener en cuenta lo siguiente: si nuestra aplicación es SEOdependiente, hay grandes chances de que estemos hablando del tipo de website que no se beneficia mucho de una arquitectura MVC, un sitio (o la parte de un sitio!) que presenta y permite navegar a través de contenidos no es un escenario muy tentador para MVC de todas formas.
Experiencia de Usuario
Si bien con PE buscamos mejorar hasta dónde sea posible la experiencia de usuario, claramente este punto lo ganan las aplicaciones MVC, en los que la experiencia es del nivel de las aplicaciones de escritorio. Claro que es posible "mejorar progresivamente" una página hasta que las diferencias desaparezcan, pero si lo hacemos es posible que nos acerquemos al problema del siguiente punto:
Servicios REST+JSON como BackEnd
Simplicidad
Si al construir el cliente web usando MVC transformamos nuestro BackEnd en un servicio REST+JSON
se mantiene toda la lógica de presentación en el cliente y se simplifican algunos problemas relacionados con la conservación de estado, como el manejo del sesiones, el ViewState, etc. el diseño del BackEnd se reduce a un caso trivial de SOA.
Basándonos en un BackEnd REST+JSON podemos mantener el más alto nivel de interoperabilidad sin demasiado trabajo extra, ya que este tipo de servicio puede ser consumido fácilmente por otro tipo de aplicaciones (de escritorio (WPF), RIAs (Silverlight), procesos batch, un widget nativo para IPhone, etc, etc), y habilitando requests cross-origin (para los recursos/operaciones deseados) tenemos una API web pública que puede ser consumida desde otros sitios web.
Por lo general en aplicaciones web convencionales el agregado de una API pública implica duplicación de trabajo agreando un servicio de estas características.
Disponibilidad
Al eliminarse la dependencia del server para la renderización de contenido, mantenemos a tiro la posibilidad de implementar un modo offline que utilize datos locales (ej. HTML5 Isolated Storage, WebSQL)
Performance
Utilizando PE es posible ahorrar muchos requests, pero sobretodo se mejora la "performance percibida" (Responsividad). Pero utilizando MVC también se reduce el tráfico de red al mínimo, la separación entre datos (JSON) y HTML no sólo permite transmitir únicamente la información necesaria, sino que ahora el contenido estático (y por lo tanto cacheable en el cliente) además de imágenes, scripts (.js) y estilos (.css) también incluye el HTML (layouts y templates)
Escalabilidad
Además de la reducción de tráfico y el uso del cache cliente, se libera al server de la tarea de renderizar html, los clientes hacen trabajar al server sólo lo necesario (para solicitar datos que no se encuentran localmente, para persistirlos, para comunicarse con otros).
Separation of Concerns o Separación de Responsabilidades
Este es la característica esencial del patrón MVC con lo cual no es extraño que incluya este punto. Si bien el título es SoC podríamos hablar más ampliamente de simplicidad y elegancia del diseño tanto del modelo de programación como de la arquitectura.
Basta con mirar la claridad que se logra en los ejemplos que diferentes frameworks MVC presentan, cualquier programador que haya trabajado en aplicaciones cuya interfaz HTML adquiere cierta complejidad habrá sentido la necesidad de un modelo superador que simplifique el código escrito.
Además llevando el patrón MVC al cliente podemos eliminar la "impedancia" que produce la división de nuestra capa de presentación entre servidor y cliente.
Esta impedancia es la misma que Asp.Net WebForms busca disminuir abstrayendo la interacción con el usuario web en un modelo de programación que se asemeja al de una aplicación WinForms (de escritorio), sin embargo quiénes hayan tenido sus luchas con el ciclo de vida y el manejo del view state, entenderán que la impedancia no desaparece.
Para terminar de ilustrar la diferencia desde el punto de vista arquitectónico en este diagrama muestro como estos dos estilos de aplicación HTML (PE y MVC) pueden impactar en la arquitectura de las aplicaciones que las soportan:
Utilicé colores anaranjados para indicar componentes que son especificos de (es decir, deben ser desarrollados para) cada aplicación.
Estos diagramas no deben tomarse como la única combinación posible, sino de un ejemplo de la forma que tomará típicamente la arquitectura de la aplicación para soportar un caso u otro.
Madurez
Este es quizás el punto que más juega en contra de los frameworks Javascript MVC existentes, las aplicaciones PE son en realidad lo más cercano a una aplicación web tradicional, es un camino muy recorrido, y esto implica las ventajes usuales:
- Experiencias previas, sin importar el problema que encaremos, seguramente encontraremos el camino muy allanado
- Hay muchos profesionales preparados para trabajar de esta forma y también muchos dispuestos a ayudarnos en distintas comunidades online.
- Herramientas, muchas y muy maduras
De todas formas:
- Las aplicaciones MVC/MVVM adquieren masa crítica muy rápidamente, probablemente ésta se convierta en la plataforma RIA de facto, no por ser la mejor de todas, los estándares en que se basa, las marcas que lo soportan, lo hacen un caso típico de profecía autocumplida
- No se trata de un entorno totalmente desconocido, se trata de HTML+CSS+JS, es en los frameworks existentes y librerías de funcionalidades aledañas (template engines, storage, etc.) dónde está la inmadurez
- En cuanto entornos de desarrollo:
- La evolución de herramientas de desarrollo en los navegadores ha hecho mucho más ameno desarrollar (y sobretodo debuguear) este tipo de aplicaciones
- En la mayoría de las IDEs existentes existe un soporte razonable para escribir Javascript, Para VisualStudio 2010 existen algunas mejoras al respecto:
Todo parece indicar que si bien las aplicaciones que llame "Progressive Enhancement" seguirán siendo las predominantes, empezaremos a ver una coexistencia entre ambos tipos de aplicaciones, y seguramente haya muchas novedades sobre frameworks Javascript MVC/MVVM/MVVM.
Si alguno tuvo alguna experiencia en el uso de Javascript MVC en proyectos reales me encantaría que la compartan,
Saludos
 Es un lenguaje común para crear test unitarios en texto plano usando el lenguaje de negocio de la misma forma que escribimos los criterios de aceptación de una historia de usuario. Esto quizás no parezca muy impresionante a simple vista, pero contar con esta declaratividad hace que los test sean fácilmente comprensibles para cualquier stakeholder, funcionando como puente conceptual entre usuarios y desarrolladores, y que finalmente sirva como documentación ejecutable de toda la funcionalidad.
Es un lenguaje común para crear test unitarios en texto plano usando el lenguaje de negocio de la misma forma que escribimos los criterios de aceptación de una historia de usuario. Esto quizás no parezca muy impresionante a simple vista, pero contar con esta declaratividad hace que los test sean fácilmente comprensibles para cualquier stakeholder, funcionando como puente conceptual entre usuarios y desarrolladores, y que finalmente sirva como documentación ejecutable de toda la funcionalidad.