Repaso en este artículo un par de propiedades muchas veces olvidadas en la definición de campos en un dataset tipado, que permiten escribir “menos y mejor código” en las aplicaciones que los usan.
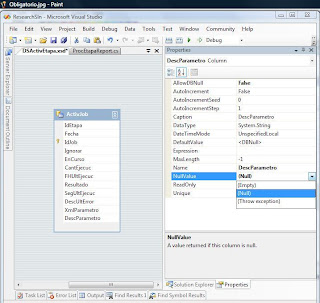 Esta propiedad, que solo puede utilizarse en campos de tipo String, permite definir el resultado obtenido al acceder al “campo” (en realidad, a la variable tipada que lo representa) cuando el mismo tiene valor null en los datos de origen.
Esta propiedad, que solo puede utilizarse en campos de tipo String, permite definir el resultado obtenido al acceder al “campo” (en realidad, a la variable tipada que lo representa) cuando el mismo tiene valor null en los datos de origen.
El comportamiento predeterminado (Throw exception) es bien conocido como fuente de errores en tiempo de ejecución, y hace que el desarrollador se acostumbre a codificar de esta forma:
Lo cual, si bien es correcto y evita los errores, requiere mucho código para una tarea simple.
Más eficiente, e igualmente seguro, sería asignar la propiedad NullValue = (Empty) , o bien (Null) si ese es el valor deseado, en la definición del campo en el dataset. De esa manera todo el código anterior se reemplaza por
en lugar de:
Importante: esta propiedad (DefaultValue) no sirve para reemplazar un valor nulo por otra cosa, al leer los campos desde una base de datos. Se aplica exclusivamente a la inserción de nuevas filas en el dataset.
Para evitar comprobaciones innecesarias, usar la propiedad NullValue
 Esta propiedad, que solo puede utilizarse en campos de tipo String, permite definir el resultado obtenido al acceder al “campo” (en realidad, a la variable tipada que lo representa) cuando el mismo tiene valor null en los datos de origen.
Esta propiedad, que solo puede utilizarse en campos de tipo String, permite definir el resultado obtenido al acceder al “campo” (en realidad, a la variable tipada que lo representa) cuando el mismo tiene valor null en los datos de origen.El comportamiento predeterminado (Throw exception) es bien conocido como fuente de errores en tiempo de ejecución, y hace que el desarrollador se acostumbre a codificar de esta forma:
if (!row.IsObservacionesNull())
obs = row.Observaciones;
else
obs = “”;
Lo cual, si bien es correcto y evita los errores, requiere mucho código para una tarea simple.
Más eficiente, e igualmente seguro, sería asignar la propiedad NullValue = (Empty) , o bien (Null) si ese es el valor deseado, en la definición del campo en el dataset. De esa manera todo el código anterior se reemplaza por
obs = row.Observaciones;
Para facilitar el agregado de filas, especificar un DefaultValue
Aunque parezca trivial, esta práctica no siempre aplicada permite que, al preparar los valores de inserción de una nueva fila, baste con especificar los campos significativos. Es decir:DSActivEtapa.ActivEtapaRow row = ds.ActivEtapa.NewActivEtapaRow();
row.IdEtapa = idEtapa;
row.Fecha = fecha;
en lugar de:
DSActivEtapa.ActivEtapaRow row = ds.ActivEtapa.NewActivEtapaRow();
row.IdEtapa =idEtapa;
row.Fecha = fecha;
row.CantEjecuciones = 0;
row.YaCompletada = false;
row.Anulada = false;
...etc.
Importante: esta propiedad (DefaultValue) no sirve para reemplazar un valor nulo por otra cosa, al leer los campos desde una base de datos. Se aplica exclusivamente a la inserción de nuevas filas en el dataset.